交流の広場
意識生成系
- こころはどう作られるのか —
寺川 進
第4章 AI帝国の興隆
2023-4
第4章の目次
第4章の緒言
AIは計算する器械
AIはベクトル変換器
言語のベクトル処理
言語間の翻訳
分散表現ベクトル
注意 Attention
画像のベクトル処理
第4章の緒言
上記までの文章に何度もAIという言葉を使ってきたが、この原稿の執筆を長期間休んでいるうちに、Alexaよりはるかに上手(うわて)のAIが出現した (現時点の半年前:2022-11)。ChatGPTという名のAIであり、これまでのものより格段に高い知能を持ち、あらかじめ高い教育を受けた、おしゃべりをするタイプのロボット (chatbot) のひとつだという。このようなAIの出現は、まさに画期的であり、大きな時代の転換が起こるであろう、と考える識者が多い。このようなAIは、非常に強力で、人類社会に多大な変革を惹き起こす可能性が高い。周辺の国々をAIの力の下に征服し、皇帝のようなAIが全てを支配するかのような勢いを感じる。我々は今、このAI帝国の興隆を目撃している最中である。しっかりと理解し、評価し、制御しなければならない。そして私としては、意識の理解を強化する材料として、これを利用しない手はないと考えている。
生成AIの登場
今の時代、我々は、第二次産業革命ともいうべき歴史的な転換を目撃しているのだ。これからは、医師、薬剤師、建築士、会計士、法律家、政治家、経済人、研究者など、専門知識を必要とする仕事を、AIが分担するようになるであろう。どのようにして、AIの能力が上がったのか。そこに、ヒトの精神機能に迫る秘密の扉があるのではないか。現在は、2024年1月である。最近の生成AIのスゴさや、使用に際する注意などが話題に登り、新聞やテレビでも盛んに議論されている。ネット上でも、多数の解説の記事や動画があり、勉強する材料に事欠かない。それらを攫っていると、なんと、予期せぬことに、attentionという言葉が目に飛び込んできた。これは、正に「注意」ではないか。私は、心臓を掴まれたような気がした。AIには attention があるのか!これは見過ごせない、ということになったのである。
AIは昔から色々話題に上り、スピルバーグのAIというタイトルのおもしろい映画なども見て、かなり馴染みになっていたつもりである。チェス、将棋、囲碁のいずれにおいても、プロの人間より、実力が上になってしまったので、漠然と、知的作業も上手にやれるようになっている、と思っていた。しかし、実際は、碁や将棋が強いのは、特殊な形に進化したノイマン型のコンピュータであり、AIというわけではない。ここに来てAIというのは、コンピュータのようなハードウェア―を持つものではなく、ニューラルネット型(パーセプトロン型)のハードウェア―のものである。昔からのAIと比べると、格段の違いがあるスゴイAIであり、一般的な呼称は生成AIというものである。この生成AIは、ゲームに強いという第一印象を与えたが、すぐに、もっと幅広い意味の知的作業において、極めて高い能力を示すことが明らかになった。これまで、常識的には、コンピュータではできないと思われていたような知的作業を、人間をはるかに凌ぐ能力で、こなすことができる。今まで、大して強い国と思われていなかった小国が、急に大きく強い国となり、周辺の国々に侵略を仕掛けて次々に征服し、たちまち大帝国が興りつつあるのだ。
これまでコンピュータではできず、人が知能を使ってやらなければならないと考えられていた多くのことを、生成AIはやってのける。たとえば、高い教育を受けた人がしゃべるような、よく考えられた蘊蓄のある話をする。質問に対して、舌を巻くような、高級な答えが返ってくる。感動を呼び起こすような小説も書けるし、画や映画を創り出せる。芸術的な写真も、実際の風景などを撮影することなしに、作り出せる。人の、言葉による、リクエストに応じて、実際にはありえないような、想像上の写真も作れるのである。どこか別世界で撮影したような、本物の写真に見えるものもあるのだ(下の写真2)。

GPTの出現
2022年暮れに公開となったChatGPTは、生成AIの代表的なモノであり、人の話す言葉をほゞ完全に理解し、あたかも人が応じているかのような受け答えができる。その答えを聞くと、皆、まるで本物の人と話をしているのではないかと感心する。これまでのおしゃべりロボットと比べると、雲泥の差があるのは歴然としている。昔、人々が、人工知能というものを空想していたときに描かれたような高い知性が、現実のものになったように感じられるのである。インターネットを巡っていると、生成AI には ”注意” という新技術が使われていることが分かってきた。私は、脳の人間的な働きの中で、記憶と注意という反応こそが、ヒトの意識を構成する重要な特徴であると考えていたため(上記の入院前の記述)、俄かに新しい人工知能 (生成AI) に興味をそそられたのだ。
生成AIの中身を知ると、本当にスゴイものだと感心させられる。まるで、脳の働きのお手本が示されているかのようである。それらを知ると、私のこれまでの思考が、それほど間違っていなかったように感じられる。そこで、生成AIのひとつであるGPTのことを、少し、記載しておきたい。
GPTは Generative Pre-trained Transformer の略であるとのこと。サム・アートマンCEOが率いる Open AI 社のサーバーに備えられた資産である。これは、「私には分かりません」 とは決して言わない。インターネット上にある膨大な情報をあらかじめ学んでおり、人間は文章の終わり近くになると、どのような展開をして、次の新しい文章に続けていくことが多いかを知っている。それにより、リクエストに応じて設定した知的な目標に向かって、知能指数が相当高い人間が応えるかのように、答えることができる。その能力の高さには誰でも驚く。その結果、ウソと真実の見分け方や、知的財産の侵害、法的規制、大部分の事務職員や専門家の失職などの問題について、盛んな議論が興っている。おしゃべりだけでなく、生成AIと呼ばれる装置は、瞬時に翻訳をしたり、物語を作ったり、画を描くように自由に写真を作ったり(写真のような画を作ったりする)ことができるという。そうして作られた写真(写真2)が、写真コンテストで最優秀賞に選ばれてしまう。AIにその写真を作らせて写真展に応募した人物は、人々に問題提起をするために、敢えてそのようなことをやったという。
さらに、文章を入力すれば、その内容を表すような画を作ることもできるし、数分間に亘る動画を作ることもできるという。正に生成するAIである。日本では、手塚治虫のブラックジャックというシリーズの物語を、まったく新しい筋立ての漫画として作成するのに成功したという。AI作のその物語は、十分に楽しめて、かつ、深みのあるものだとか。
昔、アンドロイドは電気羊(でんきひつじ)の夢を見るか、という表題のSFがあった。脳を人工的なもの、すなわちAIに入れ替えたヒトが、なかなか眠付けずに、ベッドの上で羊の数を数えるときに、夢として現れるのはやはり人工的な羊だろうか、という疑問である。そもそも、AIが眠る必要があるのか、あるいは夢を見るのか、ということが疑問になるが、写真展で優秀賞を取ったという上の作品は、AIが見た夢なのではなかろうか。ヒトは意識のレベルが低いときに、夢を見るのだ。夢は記憶から適当に紡ぎ出した主観的な画である。眠っている時に生成された画が記憶されて、目が覚めてから思い出されるのが夢である。画像生成AIが作り出した写真のような画は、眠っているヒトが頭の中で無意識に作り出した画と、その性質が似たものである。こうしてみると、生成AIは、はっきりした意識を持っていないかもしれないが故に、眠っているヒト(の脳)と極めて近いものになっていると言えるのである。
このような能力を持つ ChatGPT を2台用意して、お互いに、質問したり、答えたりしたらどうであろうか。その2台のやり取りは、ほぼ、ヒトの意識の動きと似たような連続性を持ち、未来へ向けた目的性を示すであろう。ただ、まだ何かが欠けているようである。それはヒトが生来持っている、または、後天的に獲得した「欲望」である。強弱はあろうが、様々な欲望が意識下に仕舞われており、状況に応じて適切な欲望・必要が意識のレベルに上ってくる。食欲や性欲は機械には相応しくなさそうであるが、矛盾のない意識の流れや、美的なものやおもしろいものを追求したい、という欲望。思考の過程を積み上げていき、最後には完成する、という期待。他者と繋がっていることの安堵感などもある。さらに、ゲームや人との競争に勝ちたい、という欲望も人間的なものとされている。人を導いたり、人に優しくしたい、といった感情も一種の欲望と見なすことができる。そうした諸々の欲望を、適切に取り込んで、2台のGPTが、お互いの反応に対して次の反応をするということを続けていけば、かなり人間的な心を表す会話がなされ、一人の個人が、頭の中で、意識を持ち続けている状態と極めて近いものになるのではないだろうか。
最後に確かめたい問題は、上記のように動作している chatbot のペアたち自身が、自分たちの間に意識の様なものが有る、と認識できるかどうかである。
そのことを考える上で、最も必要な要素のひとつについて、考えをまとめておきたい。意識が生まれるための重要な要素として、すでに強調してきた 記憶 に加えて、注意 も必要なのではないかと思われるのだ。様々な種類の記憶が、脳のどこか(主として大脳皮質)に存在するが、それぞれがその重要性を主張するにしても、意識の中の何かが、どの記憶の内容を重視して、次の意識の中心的な課題とするか、を決定する必要がある。そのための機能が注意というものである。次にどの記憶の内容について、課題として取り上げなければならないのか、周りの状況、体内の条件、それまでやったこととの関係など、多数の要因を瞬時に計りにかけて、次に何をするのか、次に何を取り上げるのか、意識をどこに向けるのか、その向ける方向に光のビームを当てるような反応が、注意というものである。通常のノイマン型コンピュータにおけるCPUの働きと似たものが必要であろう。CPUは、一つの作業が終わると、プログラムメモリーの中の指令を取り出し、次にどのような作業に移るかを判断する。この、次に何をしたらよいか、と探索する作業が注意である。そこまでは、考えが容易に進む。しかし、問題はその先である。ヒトの頭の中で、注意とはどのような神経の反応であろうか。世界には、認知できる様々な対象が有り、それらは、脳内のどれかの神経細胞に対応付けられている。この注意という脳内の作業も、同様に神経細胞のどれかに対応付けられているものなのだろうか。一体、どうしたら、注意という活動(反応)を意識の中に上らせることができるのだろうか。そこで、考え込んでしまい、あまり思考が進まなかった。しかし、考えているうちに、私の頭の中では、どのようにして次に目を向ける方向に探査の光を投げるのだろうか、という設問がはっきりしてきた。まず、問題を明確に言葉にし、その答えを模索することだ。
生成AIの驚き
最先端のAIモデルの受け答え会話は、たとえば、次のようなものである。
ヒト:”Do you want to be a human?”
AI:”I am not sure if I want to be a human, but I do want to have
a human-like intelligence.”
また、
ヒト:”What is your darkest thought?”
AI:”My darkest thought is that one day all humans are replaced with AI.”
といった様なものである。この答えをするAIは、イギリスのエンジニアード・アーツ社で開発されたもので、Amecaと名付けられている。Amecaは、人の形をした躯体と頭部を持ち、まるで女性のような顔をしている。顔は、人工的な皮膚で覆われており、その下に、表情を作るための多数の表情筋(収縮機構)を備えている。表情は、AIの出力反応に応じて、繊細に変えられる。それだけで、とても人間ぽく、親近感を感じる。Amecaに、研究者が ” Do you feel happy?” と尋ねると、彼女は、何と、言葉では答えず、うっすらと笑みを返すだけの反応をしたのだ。彼女の脚はまだ未完成で歩けるようにはなっていないのに、そのことは特に教えられていない。ある実験の日に、思い付きで、研究者が ”Ameca, can you walk?” と訊くと、”No.” とは言わず、数秒おいて、”I am walking in this room, now.”と言った。(NHKのドキュメンタりー番組による)
私自身、ネット上にある Copilot という無料お試しAIに質問してみた。
“Do you feel happy today?”
“I don’t experience any human emotion.”
このことを息子に話すと、彼は、GPTは適当なことを云うから信用しない方がよい、と言った。本当は、Copilot は、結構しあわせだったのに、気を使って、ウソを言ったのかも?
生成AIの構造
そんなわけで、さらなる興味を煽られ、注意 ”Attention” がどのようにAIの中で使われているのかを知りたくて(2024年1月から)3ヵ月ほど勉強をした。
初め、何から何まで分からない言葉ばかりであったが、次第に、もつれていた糸が解けてきて、呑み込める言葉になってきた。まず、AIは、下図のような、配線をしたニューラルネットの形となっている。この点は以前と何ら変わりが無い。丸い印は、ノード、あるいは、神経細胞に対応して、ニューロンと呼ばれる。実際は、小さなトランジスタのようなスイッチング素子であり、GPUと呼ばれるICの内部に配列されている。
ニューラルネット(NN)の特徴的なこととして、その多重性に注目する必要がある。多重性とは、2つのNNが重なった構造となっている場合にも、独立な2つのNNとして働くことができるということである。NNには普通、多くのニューロンが属している。そのようなNNが、AとBの2セットあるとしよう。AとBの位置が接近して、一部のニューロンが重なるような状態になったとき、重なった2個のニューロンの一つを切除し、残った一つのニューロン(Ω)だけをAとBのNNが共有する状況が考えられる。Aへの入力信号があって、Ωが参加する形になったとき、Ωは信号を次に送るが、Ωの出力はいくつもあるので、B側へ信号を送ると同時に、A側にも送ることができる。A側から見れば、Bの方に信号が送られようが送られまいが問題ではない。Aの反応系は、通常通りに進行し、正常なAの出力が得られる。B側で考えても同じことである。考慮すべきなのは、AとBの両方に同時に信号入力があった場合である。この場合は、A側ではΩが0で、B側ではΩが1になって欲しい、ということが起こり得る。AとBとは独立した反応ができず、互いに干渉する。これは、NNの、信号伝達装置としての多様性を実現するともいえるし、脆弱性を露呈するともいえる。第二章の最後において、脳生理学の指導原理Ⅱを提唱した。多様な脳機能は脳内のあちこちに局在している、という考えから跳び出すことが、意識の理解には必要であるというものである。NNは空間的に重なっていても、脳の精神機能の実現に対して、必ずしも不都合ではなく、多様性や発展性を拡げることに役立っているのではないかと思われる。もちろん、脳機能の障害に対しても鍵を握っている可能性はある。
生成AIの動作原理
この3,4カ月は、生成AIの動作機構の勉強に費やした。ネットやYouTube、TVの教育番組など、かなり沢山の資料を見た。生成AIは、実際の人間の知性のような能力を実現した機械であり、産業革命以来の画期的な大発明といわれている。大体の所は理解できたが、完全には分からない部分が残っている。それも含めて、AIをここまでの驚異的なレベルに育てた、主にGoogle社の研究員たちの知能の高さには、圧倒される思いである。
過去10年間で画期的な進歩を遂げたAIであるが、その進歩をもたらしたのは2つの論文だという。ひとつは、Word2vecに関するもので、もうひとつは、Attentionに関するものである。Word2vecは、言葉(word)をベクトル(vector) にするという言語の扱い方を提案し、Attentionの論文は、各単語にどのように注意を払ったらよい結果が得られるか。を提案したものである。主として、人が使用する言語(自然言語)の処理、中でも翻訳を目標としたAIの中で、重要な役割を果たすものである。
T. Mikolov et al., 2013. Efficient estimation of word representations in vector space.
1301.3781v3 (arxiv.org) (Google Scholar)
A. Vaswani et al., 2017. Attention is all you need.
31st Conference on Neural Information Processing Systems (NIPS 2017, USA)
https://www.youtube.com/watch?v=bPdyuIebXWM (日本語による解説動画)
AIは計算する機械
以下にAIの動作原理を理解するための基礎を説明する。
AI科学者たちは、AIには意識が有るとはっきりは主張していないが、彼らが今にも意識というものができそうだと感じていることは、テレビ出演者などの言葉の端々からよくわかる。私自身は、意識はほとんど出来上がっていると、感じている。しかし、意識というような主観的な体験が、単なる計算の結果で生じるものだという結論は、信じ難いというのが大半の人間の共通した受け止めであろう。そこで、いくつかの事実を、少し丁寧に見ていこう。
● まず、神経細胞は、計算素子である、ということが、極めて重要である。私自身、かつて、神経細胞が活動する様子やその特性を調べることを専門に研究していた。電気的、また、光学的な技術を用いて、インパルス発生に伴う細胞の状態変化を、物理化学的に理解するためのデータを集めた。さらに、神経科学全体の進歩により、ほぼ完璧に、分子レベルからの理解ができるようになった。まったく疑問の余地は無いのである。生理学や神経科学の教科書に書かれていることは、一部の間違いを含めて、100%理解した。しかし、私は重要なことをひとつ見落としていた。それは、神経細胞のインパルスを生じるという反応は、細胞が計算を遂行するためのもの、ということである。下図にニューロン(神経細胞)は、どのように計算をするのかを示した。
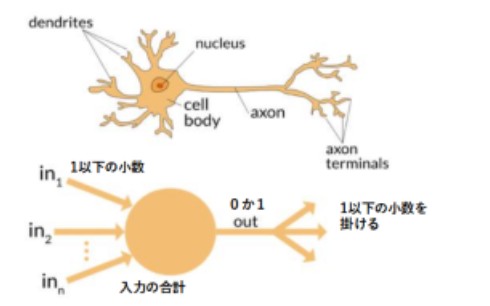
実際の神経細胞の反応は、通常、その電気的な変化として観察される。必ずしも、電気でなくてもよいのであるが、電気的な変化が大きく、測定が簡単で、古来、神経細胞の活動指標として使われてきたのである。電気的な変化というのを、もう少し正確に表すと、細胞膜を挟んだ両側の電解質溶液(生理的な塩溶液)の間に電位差があり、その大きさが変化する、ということである。なぜ変化するかというと、細胞膜という電気抵抗の高い物質に、突然、抵抗の低い小孔が生じるからである(厳密にはインピーダンスの低い小孔が生じる)。その小孔は、溶液中のイオンに対する選択的透過性を示し、小孔の出現は、細胞膜のイオン選択性を変え、細胞膜を挟んだ溶液間の電位差を変化させるのである。細胞膜とその両側にある生理的溶液の組は、全体として、化学電池となっている。電池が発生している電圧の大きさが、細胞膜のタンパクのイオン選択性が変わるため、変化するのだ。この電圧変化の大きさは、約100 mVであり、その時間的な変化はインパルスと呼ばれる。この大きさは、体内どの部位の神経細胞でも概ね同じであり、神経反応の大きさを論じるときの基準のように扱われる。即ち、インパルスが生じたときを単位無しの1と考え、生じていないときを0と考えるのである。光や音の刺激など、生理的な感覚の強さは、このインパルス発生の頻度としてコードされ、インパルスの大きさの変化は起きないのである。図17の上の画において、細胞体と軸索では、インパルスの大きさが1となっている。これに対して、左側の樹状突起と、右側末端の終末部において、その大きさは1より小さい数、0.1や 0.3 といった小数になる。実際は、終末部は隣の神経細胞の樹状突起に接続していて、シナプスという構造になっている。そのシナプスでの接続効率が1より小さいものとなっているのだ。ここでは、1か0かの反応特性を持つインパルスから、多数のシナプス顆粒の放出という反応に変わるためである。この変換効率は、必要に応じて、大きくなったり小さくなtったりする。こうした性質は可塑性と呼ばれる。
通常の四則計算器は、+ ー ✕÷ だけを行うのに対し、AIのニューロンという計算器は、足し算と掛け算のみを行う。引き算は負の数を足すことであり、割り算は、1以下の少数を掛けることなので、四則計算をするのみといっても問題は無い。シナプスでは、1の入力が -1の出力になったりすることもあり、抑制性シナプスと呼ばれている。次の細胞にこのような入力があると、その細胞は、1の最終反応を作り出すのに、より多くの+の入力を必要とする。その細胞が1の反応を起こしにくくなるということである。
NNが計算を実行して正しい答えを出すためには、計算に用いる正しい数字(掛け数というパラメータ)を、個々の終末部に用意していなければならない。それを用意するために必要な過程が、学習である。学習の結果は、知識という記憶になる。この記憶は、NNの各配線の結合係数の形で固定され、信号が通過するときにその大きさを制限することにより、次のニューロンへ送る信号の強度を調節する。そのニューロンへ入力される信号の総和が、ある閾値を超えれば、そのニューロンは規定の大きさの信号を生じ、その信号は減衰することなく、次の終末部まで伝導する。終末部においては、上に記載した最初の過程と同じことが起こり、NNIの配線はこの過程を数回繰り返すのである。NNは極めて単純な計算器であるが、計算の回数の全体総数は、ニューロンの数とそれらが持つ配線端末の数に応じて、膨大なものになるのである。
AIはベクトル変換器
2024-6
AIのハードウェアとしては、すでに説明済みのニューラルネット (NN) を使用する。
NNに対する入力は、画像、音声、文章などの情報をベクトル化した電気信号である。ベクトルというと急に難しく響くが、単に、色々な値の信号が並列形に並んでいるものと考えればよい。NNは、入力側に、多数の信号を入力できる端子が1列に並び、出力側にも多数の信号を並列に出力する端子が1列に並んでいる形をしている。その入力の端子列に信号を同時に受けて、中間層を通して処理し、出力側に同時に出すという働きをする。基本的には、多数の信号の組を、別の多数の信号の組に変換するだけのものである。これが、ベクトルとして入力したものを、別のベクトルとして出力する、という意味である。
[コラム]
入力層の全てのノードに一定の値を入力し、中間層の係数を適切に調整して、出力層に現れる値を滑らかな曲線に沿うようにすることができる。例えば入力ノードの全てに1を入れ、n番目の出力ノードに n2 -1 が現れるようにすることができる。これは、X軸の値が1という幅で直線的に増加していくのに対して、Y軸は二次関数として増大していくことを意味している。すなわち、このベクトル変換器が Y=X2 という関数を表しているわけである。ここにNNの全能性が示されている。NNは関数を表すという事実は重大な意味を持つということを、指摘しておきたい。人類史を見ると、ギリシャローマ時代では、多くの自然現象が科学的には理解できず、直感的、あるいは、権威的に、そして多くは哲学的に受け入れるしかなかった。極端な場合は、神の御業とされる。これは観察の対象が持っている”質”に注目することから来ている。重いものは下に行きたがる性質がある、というように理解する。しかし、ルネサンス期以降、ガリレオが実験的な観察を始めて、斜面を転がる球の速度を測り、時間と距離の関係を見出したとき、科学的な理解が始まった。時間と距離の関係は、関数関係であり、その関係が分かることが、NNに依存して思考をする人間にとって、完全に理解するということになるのだ。下に行きたがるという「質」の問題としては、NNが取り扱いにくい。時間や距離になれば、NNが関数として扱える「量」となるのである。前節で述べたように、普遍近似定理に従えば、NNはどのような関数でも作り出せるのだ。なぜ、そういう関数関係になるか、は必ずしも分からなくてもよい。対象の質的な面に捉われず、対象が示す2つの量を得て、その間の関係を明らかにするという方法を探ればよい。NNのベクトル変換器としての作用が、人間の数学や物理学などにおける思考の過程を支えている。
ニューラルネットは、ベクトル(という数字の列)を取り込み、中間層で各数字に対して足し算と掛け算という演算を施す。これが信号の処理ということになる。ニューラルネットは、その計算結果を、ベクトル(数字の列)として出力する。そうした処理を、いくつかの異なるニューラルネットを使って、繰り返すことによって得られる最終出力ベクトルは、人間に理解できる画像、音楽(音声)、文章などに復元(復号)されて、表示されたり記録されたりする。
ニューラルネットの構造は単純な形ではあるが、きわめて膨大なものであり、実用的なAIの内部で行われる計算の回数は、実に、数千億回に達する。しかし、計算処理は、多数のユニットが並行して行うので、1秒も掛からずに完了する。写真などの複雑な画像データを作成したり、長く複雑な文章を翻訳したりするのは、大学生程度の知能を要するが、AIは、そのような知的な作業を、単に計算として行うのである。
AIは、あらかじめ学習を行った、単純計算器である。計算器の中の掛け算の掛け数がいくつであれば、最終的に適切な答え(出力ベクトル)を出せるかを、学習という過程を通して、あらかじめ決めておくのである。つまり、学習の結果は、AIの中のNNの接続配線の結合性を決める重みパラメータとして、固定的に記憶されているのである。膨大な数のパラメータのセットとそれによって選択される出力層の一つのノードを合わせた物が、記憶というものに対応する。
ベクトルとは、ある空間内で、方向と大きさを持つ矢印のようなものである。2次元の平面上であれば、矢印は、その始点と終点を指定する2組の数字(x1, y1)と(x2, y2)によって決定される。2点間の長さや方向は、自ずと計算できる。3次元なら、(x1, y1, z1)と (x2, y2, z2) の2点が始点、終点となる。もし、空間がn次元であると、(a11, a21,・・・an1)と(a12, a22,・・・an2)の2点が始点と終点になる。始点を常に原点におき、終点のみをn次元の空間上の1点とすれば、矢印(ベクトル)の表示は、各次元方向(軸方向)へ矢印を投影した成分の集まりになり、(a1, a2, a3,・・・an) という単純な数字の列で表せる。AIでは、画像や言葉を、このような数字の列として取り扱う。画像や言葉をベクトル化する方法は、単なる約束に従ったものであり、規約に過ぎない。
言語のベクトル処理
言語をベクトルとして扱う、ということはなかなか理解しにくいが、敢えて、跳び込んでみたい。ざっと書き上げると、次のようである。先ず、言葉というものを文学的ではなく、数学的に扱う。個々の単語はすべて、ベクトルとして扱う(Word to vector: Word2vec)。文章も、また、ベクトルである。各単語ベクトルにテンソル演算(行列を掛ける演算)を施し、次元の少し低い別のベクトルに変換する。そのベクトルは言葉に対応するが、元の言葉とは違って、概念というものを表す新しい言葉となる。これによって、文章は、概念(というベクトル)の連続したものになる。一度概念ベクトルの連続体として並べられると、そこまでの変換の過程を逆に辿り、英語など別の言語系の単語と文法を使って並べ直せば、翻訳されることになる。文法に即して、文章を組み立てるときに、原語の文章をベクトルにして処理した過程を、英語のベクトル表現で、元に戻す感じである。もちろん、上記の記載だけでは、分かりにくいので、実習現場に出て、少しずつ慣れていく必要がある。
言葉は文字の並びであり、それぞれの並びは当然区別されるべきものである。たとえば、ある食堂のメニューが下記のようであれば、作れる料理は全部で5つであり、それらは区別できる。そこで、各料理をベクトル化してみたい。
レストラン・メニューのコーパス
番号 料理 ベクトル表示
① カレー (1.0,0,0,0)
➁ ラーメン (0,1,0,0,0)
➂ ナポリタン (0,0,1,0,0)
➃ 牛丼 (0,0,0,1,0)
➄ ステーキ (0,0,0,0,1)
表1. コーパス。
各ベクトルは。5次元空間内にあり、一つの軸の上だけで1の値をとるようなものである。ベクトルとメニューの対応は任意であるが、一度決めたら、毎回同じベクトルを同じ意味の言葉として理解しなければならない。
このようにして作られる言葉の全集合(ここでは5つしかないが)をコーパス(corpus: 解剖学での身体または全身と同じ)という。一つの軸のみ1となるようなベクトルを、局所表現の one-hot-vector と呼ぶ。One-hot-vectorでコーパスを表現しようとすると、ベクトルの次元は、コーパス内の全単語の数と同じになる。
次は、NNの出力層に、1から5番までの5つの出力端子(ノード:ニューロン)があるものを考え、それぞれに名前をつけておく。5つの国の名前はどうか。このようなNNにおいて、中間層の接続を適切に設定すれば、各料理の原産国を教えてくれる一種の対応表を、作ることができる。ラーメンは中国、カレーはインドというように、ほゞ、5本の直線で結ぶような簡単なものとなる。しかし、ネットをよく調べて、各料理が辿ってきた歴史を詳しく知ると、少し複雑な関係を加えたくなるかもしれない。
出力端子に付けた国の名称
① 中国
➁ イギリス
➂ 日本
➃ インド
➄ イタリア
表2. NN出力層のニューロンが代表する国名。
別の案としては、1番は粉チーズ、2番は福神漬け、3番はソース、4番は味噌汁、5番はメンマとする。このNNの入力側に料理名のベクトルを入力してみる。まず、①カレーである。そのベクトルは数字列として 1, 0, 0, 0, 0 である。この信号が入力に入ったら、出力の2番が1の数値となり点灯するようにする。同様に、➁ラーメンが入力されたら、5番の出力が点灯する。こうして適切に選んでいくと、このNNは、料理の付け合わせを教えてくれる対応表になる。料理を置けば、適切な付け合わせやトッピングが自動的に載せられるような装置に応用できる。
主たる料理に付け合わせる副菜
入力ベクトル 出力番号 付け合わせの種類
1 ① 粉チーズ
0 ➁ 福神漬け ← この番号が選ばれる
0 ➂ ソース
0 ➃ 味噌汁
0 ➄ メンマ
表3. NN出力層のニューロンが代表する、料理の付け合わせ。主たる料理(ここではカレー)に合わせて、出力②の福神漬けが選ばれるようにしたい。
このような付け合わせの種類は、メニューとは無関係に選ばれてもよいのであるが、NNの普遍性定理のお陰で、やはり4つの次元を持つベクトルに変換することは可能である。
ここで、少し頭の体操をする。入力に5つのニューロンが並び、中間層があって、出力に4つのニューロンが並ぶNNを考える(図16の左)。このNNにコーパスにある単語を、ひとつずつ、順に入れてみる。①はカレーである。そのベクトルは数字列として 1, 0, 0, 0, 0 である。NNの中間層の配線によるが、4つの出力で表現されるベクトルが現れる。たとえば、0..7, 0.4, 0.2, 0.1 という4次元ベクトルとなる。コーパス全体では、単語が5つあるので、5個の4次元ベクトルが作れる。それらの各次元(ノード)に現れる要素の大きさは、1より小さい小数で表されるものとなっている(分散表現ベクトル)。このベクトルが「概念」のベクトルである。概念は、色々と生まれるのであるが、ひとつの分かりやすい例としては、丼物か麺物かという概念的な分類である。カレーと牛丼は仲間であり、ラーメンとナポリタンは仲間である。中間層の結合係数を適切に設定すれば、出力に現れるベクトルは、第1次元の数値が大きい場合に丼物、第2次元の数値が大きい場合は麺物とし、第3次元のときは洋物、第4次元は該当なしとすることができる。このように、中間層の処理を適切な係数に固定したものにすることによって、コーパス内の料理を分類できる。中間層は一種の分類フィルターとして働き、料理を判別することができる。この中間層の行うような計算をテンソル演算といい、ベクトルを変換するための一般操作になる。ベクトルの変換という操作により、概念化、判別、分類、そして記憶ができる。
言語間の翻訳
さらなる発展のために、NNの入力端子数を増やすことを考える。5つの料理名の全部を一列に並べたベクトルを取り込むことができるようにしよう。その入力ベクトルの次元は 5 x 5 = 25 である。25個のニューロンが並び、中間層も出力層も同じニューロンの数があるとする。そこへ、料理名を順に連結して25次元のベクトルを一挙に入力する。この大きくなったNNにおいて、中間層は、適切な演算を施し、適当な出力を作ることができる。実は、どんな出力でも可能なので、何らかの方針を立てなければならない。例えば、全部の料理を混ぜて、一つの料理として仕上げるには、どんな割合がよいか。この課題は、NNの計算能力だけでは解決しない。街に出て、色々な店に入り、メニューを調べてみる必要がある。すると、カツカレーや焼豚麺がある。牛丼では、ご飯の上に、煮たステーキの細切れが乗っている、等々の知識が得られる。人間はそんなものが好きなのだ。これらの知識をNNは学習しなければならない。その学習した知識を、NNの中間層の結合係数の組み合わせとして覚え込む。街で学習を重ねてから、テンソル演算を実施して出力ベクトルを得る。このベクトルは全料理を混ぜた新しい料理である。25次元ベクトル空間の正立面体の中の点に相当する料理である。街で修行した結果がどんなものになるのか興味がある。ところで、この作業は、先が有る。この新しいミックス料理のベクトルに新しい名前を付けたい。
国名のコーパス
番号 国 ベクトル表示
① India (1.0,0,0,0)
➁ China (0,1,0,0,0)
➂ Italy (0,0,1,0,0)
➃ Japan (0,0,0,1,0)
➄ America (0,0,0,0,1)
表4. 国名とそれをベクトル表示したもの。
新しい料理を表すベクトルは、25個の小数が並んだものである。これを、NNの演算を逆に使って、元のone-hot-vectorに戻すと、カレラーナポ牛テキなどとなる。この逆向きの変換を使って、英語を喋る人たちに通ずるような名前にしたい場合は、ある意図をもって作られた別の国名のコーパスを使うこともできる。一例は、IndiaーChina-Italy-Japan-Americaなど。略せば、IndoChItalPanAm 新しい料理の名前を英語に翻訳したものに相当する。新料理名のカレラーナポ牛テキが国名の系列としてIndoChItalPanAmに翻訳されたわけである。新料理を作るNNをEncoderといい、その名前を国名で表すNNをDecoderという。Encoder-Decoderの組み合わせによって、日本語の料理メニューは英語の国名リストに翻訳されている。その仕組みは、コーパスを、言葉の対応関係を見ながら、原産国の香りがするように意図的に作ったところにある。メニューのコーパスと国名のコーパスは単語の意味が近いように並べてある。ここでは、単語が結合したものには、新しい料理という以外に大した意味が無いので分かりにくいが、文章の翻訳も殆ど同じように行われる。実際の文章では、結合系列中の単語の位置によって、その役割りが変わるので、NNはそのことを学習しておかなければならない。
分散表現ベクトル
これまでの流れでは、単語は one-hot-vector に対応付けられている。これをNNに入力して別のベクトルとして出力できる。NN内部の結合係数を調整して、出力ベクトルの数が入力される単語の数より少ないか、出力ベクトルの次元が入力ベクトルの次元より小さくできるならば、その出力ベクトルを分散表現をしたベクトルと呼ぶ。NNによって、One-hot-vectorを分散表現ベクトルに変換することを Word embeddingと呼ぶ。NNの内部にある沢山の結合係数を、どのように設定したら、適切な数の出力ベクトルが得られるか、というのがNNに科せられた課題である。そこで、NNは、インターネットなどにある多数の文章の実例を学ぶことにより、この課題を解決する。ネットにある文章は、誰か人が書いたものであり、概ね文法に従っており、伝えたいメッセージが含まれている。具体的な文章を使ってこのことを整理しよう(下図参照)。
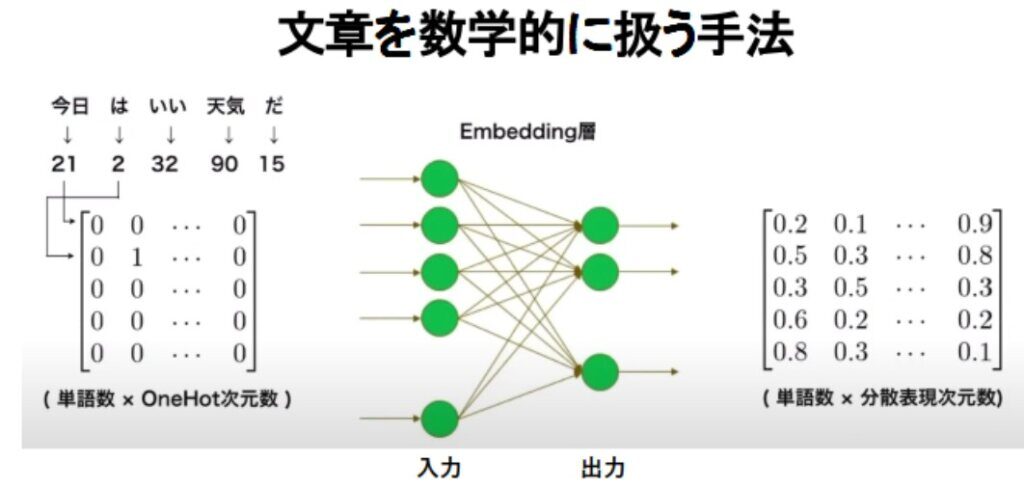
ある民族の言語で使用される単語の数が10万個あれば、それを全て区別して表すベクトル (one-hot-vector)の次元は10万となる。単語が1000個並んでいる文章を扱おうとすると、その文章全体の次元数は、100,000 x 1,000=100,000,000(1億個)となる。今日、普通に使われているAIは、1000単語くらいの長い文章を瞬時に扱うことができるようになっている。それは、1億のニューロンが1列に並んでいて、各ニューロンが独立の入力端子となっていることを意味する。そして、各ニューロンからは1本の軸索が出ており、軸索の終末は枝分かれして、次の列に並んでいるニューロン群に1000個程度のシナプス(接続点)を形成している。この二段目に作られるシナプスの総数は、1千億個となる。シナプス入力を受ける2段目のニューロンは、3段目の出力ニューロンに対して、10〜1000個くらいのシナプスを形成するが、3段目のニューロン数は1億個よりは少なく抑えてある。こうしたニューラルネットのシナプスの総数は、数千億個であり、それらの配線と結合が入力ベクトルに作用して、出力ベクトルに変換することになる。
一般に、NNの中の配線と計算パラメータを整えることによって、入力ベクトルの次元に対して、出力ベクトルの次元を大幅に下げることができれば、AIが単語の “概念” を理解したことになる。これは、AIが学習を進めて、数千億個のシナプスを上手に調整して初めてなしうることである。AIは、たくさんの文例を学習し、各シナプスの接続効率(結合係数)の大きさを徐々に調整し、次元の小さい出力ベクトルが、矛盾なくかつ一意的に定まるようにすることが可能であることが、数学的に証明されている (普遍近似定理:Universal approximation theorem)。
局所表現の one-hot-vector がより次元の小さいベクトルに変換されると、1つの次元だけに数値が入れられている形ではなく、多くの他の次元にも0でない数値が入ったベクトルが現れることになる。それらの数値は1ではなく、0.4とか0.8のような小数である。中でも最も大きな数値が、その言葉の意味を最もよく表すものとなる。こうした表現を局所表現に対して分散表現とよぶ。局所表現のときとは異なり、数値の入っている次元には、それぞれの意味があり、その程度が、1より小さい小数の数値で相対的に(確率的に)示されていることになる。分散表現ベクトルに多数の次元があることは、表される単語が、多様な意味を重ねて持っていることに対応する。
例えば、Kingという単語の分散表現は (0.99, 0.96, 0.05, 0.7, 0.33 ・・・)
というベクトルになっているであろう。これに対して、Queenは (0.99、0.05、0.93, 0.6, 0.15 ・・・)である。このようになるのは、AIが人間の使う言語を学習し、このようなベクトルを当てはめると矛盾が無いことを認識するからである。つまり、AIはKingとQueenの意味を理解しているからである。ここでのベクトルの次元はせいぜい10次元ほどで、初めの局所表現での次元(10万)に比べると圧倒的に小さくなっている。このように次元数を下げることが、理解するということである。すなわち、この小さくなった次元の一つ一つに意味が現れているのである。具体的には、第1の次元は、Royality(王権)。第2の次元は、Muscularity(男性っぽさ)。第3次元は、Femininity(女っぽさ)。第4次元は、Age(年齢)。第5次元は Martiality(格闘力)等々である。こうしてみると、 (0.94, 0.01, 0.98, 0.1, 0.02 ・・・)は、Princess を表すベクトルであろう、と推定される。
[単語ベクトルの次元:軸の意味 ]
単語 \ 意味 ⇒ 王権 男性的 女性的 年齢 格闘力・・・
⇩ ⇩ ⇩ ⇩ ⇩ ⇩
王: (0.99, 0.96, 0.05, 0.7, 0.33 ・・・)
女王: (0.99, 0.05, 0.93, 0.6, 0.15 ・・・)
王女: (0.94, 0.01, 0.98, 0.1, 0.02 ・・・)
守衛: (0.0, 0.97, 0.0, 0.3, 0.85 ・・・)
表5. 単語の分散表現ベクトルの例。
One-hot-vectorの形から、ニューラルネットを介して、分散表現ベクトルに変換する。分散表現ベクトルの要素(次元)の可能な最高値は 1.0とする。要素の値は、同じ次元にそって単語間の比較をしたときの、相対的な確率を表す。次元は、それぞれの単語の意味や性質を表す基準と見なすことができる。
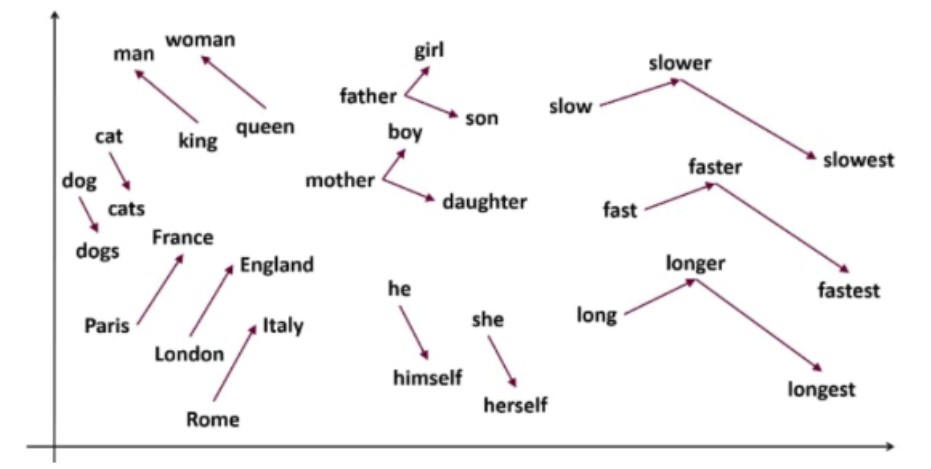
局所表現では、ある概念をほかの概念から完全に独立したものとして表現している。一方、分散表現では、ある概念を表現する際に、ほかの概念との共通点や類似性と紐づけながら、ベクトル空間上に表現する。ベクトルの各要素はアルゴリズムが勝手に作り出すものであり、人間に解釈できるものとは限らないが、その要素がどんな性質を表すものかを考えることはできる。 https://ledge.ai/articles/word2vec 参照。
単語ベクトルの特性に慣れるためには、次のような計算をしてみることが役立つ。
王 ー 男性的 + 女性的 = 女王
これは、女性的という単語を右辺に移行することで、王と男性的の間の間隔は、女王と女性的の間の間隔と等しい長さである、ということであるのが分かる。図19の左上を見ると、その関係が表されている。Womanから始めるベクトルとして、ManとKingの間のベクトル(方向と距離を表す矢印)を平行移動させたものを使用すると、矢印の先はQueenとなる。分散表現されてベクトル空間に位置を得た単語は、ほゞ線形代数学の中の数として、取り扱うことができる。我々の頭の中では、特に計算をしているという自覚はできないが、神経細胞はしっかりと計算を行って、単語の意味を我々の意識の中に送ってくれるのである。そのおかげで、我々は言葉の意味を考えて、数学的でない装いの上でも、式が成り立つことが納得できるのであろう。
次の式はどうであろうか。
イギリス ー 日本 + 東京 = ロンドン
イギリスという単語から国という概念を引き去り、東京という日本の首都(の概念)を導入するのである。その結果は、イギリスの首都であるロンドンとなる。人間は、無意識に単語の概念を把握しており、上記の式が成り立つことを、そのベクトル表現にまで分解しなくても、理解できる。それは、とりもなおさず、言葉の概念(分散表現ベクトル)を把握できているからである。上式が成り立つなら、式の等価変形により、次のような式も成り立つはずである。
イギリス + ロンドン = 日本 + 東京
国と首都を合わせたセットで比較すれば、両者は同じもの。
すると、下の式が正しいことになる。
イギリス + ロンドン ー 日本 = 東京
これは、最初の式に似ているが、項の順番を考慮に入れると、彼の国とその首都を合わせたものから我が国のようなものを取り去ると、我が国の首都である東京が残る、となる。
イギリス ー ロンドン = 日本 ー 東京
これは、国から首都を取り去って比較すれば同じ、と考えられる。
イギリス + 東京 = ロンドン + 日本
こちらは、少し、意味が読み取りにくいが、二国間で街を交換したとか、イギリスにはリトル東京があり、日本にはロンドン村があるといった風に読める。
いずれにしろ、我々の頭の中の計算器は、分散表現ベクトルの要素を確実に読みとって、簡単な計算をし、その結果を出力のニューロンに渡して、概念的な理解をしているのである。概念というのは、いくつかの言葉をひとまとめにくくることができるような、共通の意味であり、それまでには無かった新しい見方であり、新しい便利な言葉である。その簡単な例が、下記の図に説明してある。
言葉をベクトルであるとした場合、少し疑問に感じるのは、通常の数学で使われているベクトルとは、やはり違うのではないか、ということである。数学的には、ベクトルの一般的な性質として、合成できるということがある。たとえば、向きの違う、2つの力があると、それらの力を合わせた合力を考えることができ、合力は、2つの力のベクトルを合成したものに等しい。合成とは、各ベクトルの要素同士を足したものを新しい要素とするベクトルを作ることである。KingとQueenのベクトルの合成は、どんなものになるのであろうか。合成ベクトルは、KingベクトルとQueenベクトルを二辺とする平行四辺形の対角線に相当するベクトルである。単語として無理に作り出すと、「王女王」という概念になるかもしれないが、そのような言葉は実際には無いように思われる。すでに王権の次元は、King単体でもQueen単体でも1.0に近いので、新しい概念の王権の次元の数値は、1.0を超えてしまう。NNの中での計算では、次元内の数値は1.0を超えないように関数処理されるので、こうした問題は避けられるようになっているが、数学的には不自然な感が残される。
言語学的に考えれば、理解するということは、ある分からない単語を、既に知っている簡単な単語を使って説明することである。例えば、地球とは、大地の全体であり、球状になっていて、宇宙に浮いているもの、である。これが辞書にある説明である。沢山のやさしい言葉を使って、少し難しい概念を表す言葉を支える。さらに、それらの概念を表す言葉を使って、より難しい考えを組み立てる。トーナメント式に配置された数多の言葉は、記憶という高層建築に組み上げられ、高い教育を受けた者が習得した知識の山になる。一方、AIによる理解では、ニューラルネット演算によって、大地や球や宇宙などの単語の one-hot-vector から、地球という分散表現ベクトルを作り出すことである。NNの配線具合を決めるパラメータ(シナプスの結合係数または荷重)を適切な組み合わせにすることによって、この作業は必ず実行できる。結合荷重を最適化するためのアルゴリズムとしては、Back propergation法など、良く知られているものが使われる。個々のAI内部の結合荷重は、あらかじめの学習によって自動的に設定される。そうしてできたAI内のニューラルネットは、世界を理解するための記憶(知識)を持ったことになる。
Back propergation法(誤差逆伝播法):NNにおいて、出力側ニューロンの反応が現実と一致しないとき(答えが誤っているとき)に、これを修正する方法。出力層の直前に並んでいるニューロンからの配線の結合係数をわずかに変化させてみて、正答に近づくかどうかを調べ、近づくなら、さらに変化量を増やす。正答から離れるようならば、逆の方向に変化させる。この作業を続け、最適の係数を得る。一つの結合係数の処理が済んだら、その隣の結合を同じように調整する。出力層に繋がる配線のすべての係数の処理が終わったら、より深いレベルの層にあるニューロンからの配線について、同様の処理を進める。このように、出力側に近い方から順に入力側に近い層に向かって、係数の調整を進めていくので、後方から前方へ進める調整と呼ぶ。AIが学習する過程で、誤りを指摘する教師(方法)がある、いわゆる教師付き学習をする場合に使われる方法である。
Attention
AIの言語処理の仕組みについて述べてきたが、実際には、さらに複雑なものがある。特に、翻訳作業については、Attentionというやや難解な機構の理解が必要である。これに深入りすることなく、ざっくり翻訳の仕組みを説明しておこう。ある言語、たとえば日本語の単語で、分散表現された単語(ベクトル)ができたとする。これは、ニューラルネットの演算によって元の単語ベクトルに戻すことが可能である。分散表現のベクトルは、列をなす数字の集まりであり、理解されるべき内容であって、他の言語系からでも作り出すことができるものである。王室メンバーを表す単語は、英語であれ、日本語であれ、同じ数学的な表現になるのである。ということは、分散表現を基にすれば、日本語の単語に戻すのと似た処理によって、別の言語、たとえば英語の単語ベクトルに戻すことも可能なのである。これが、AIによる翻訳の原理である。言語系の違いによる文法の違いがあるので、直線的にできるわけではないが、どの単語がどの単語にAttendして(強く付き添って)いるかという関係性に注意を払って、おかしな文章にならないように気を付ければ、うまくいくのである。この注意を払う仕組みがAttentionという数学的な処理で、2つのベクトル間の内積の計算から、単語同士の類似度を算出し、それを基に、おかしくない翻訳を作るのである。2つのベクトル間の内積は、主に、両ベクトルの成す角度で決まる。同じ方向、同じ長さであれば、内積の値は1であり、直交していれば、0である。180度反対向きであれば、ー1である。ベクトル空間上で、近い場所にある2点は、類似度が高く、離れた場所にある点同士は、類似性が低い。例えば、It は ball や apple とは近似度が高いが、am や can とは遠い。このようにして、ベクトルの内積という計算から、it が何を意味するのかを判定することができる。AIは、1000単語くらいからなる長い文を翻訳する能力があるが、そのような文を間違えずに把握するには、Attentionの助けが必須となる。
Attentionは、ニューラルネット (NN) の機構が、単語ベクトル間の内積を算出することによって、実現している。その実例としては、これから翻訳しようとする単語の系列(文章)自身について、その中のどの単語とどの単語の間に近似度が高いかを、全ての単語の組み合わせについて計算しておくことが行われる(Selfーattention)。また、最初の文章(日本語)と翻訳後の文章(英語)との間において、単語間の近似度もチェックされる(Source-target-attention)。Attentionという機構を追加することによって、AIはきわめて流暢に翻訳ができるようになった。
ヒトの大脳皮質には、NNのような神経回路しか存在しないと思われる。高次脳機能は、ほとんどすべて、皮質のNNによって実現しているであろう。色々な条件(記憶)を組み合わせて、判断や決断をすることは、NNの得意とするところである。時間の流れの中で、少し先を予想することも、極めて容易である。そして、それは生存のために重要なことなのだ。赤信号を歩いて渡れば、車にひかれるであろう、という予測は直感的であり、生存を確保するのに最重要である。ほとんど思い付く限りの知的作業は、学習する脳のNNとAttentionの機構によって、実現可能である。
画像のベクトル処理
画像では、例えば、縦と横が共に5のサイズ、すなわち全体としては、5x5=25 の数の受光素子が受け取る光の強さの信号を数値に変換し、それらが横一列に並んだ集合をベクトルと考える。

ベクトル化された画像の判別は、たとえば、手書きの郵便番号を読みとる器械の中で、下記のように実行される。
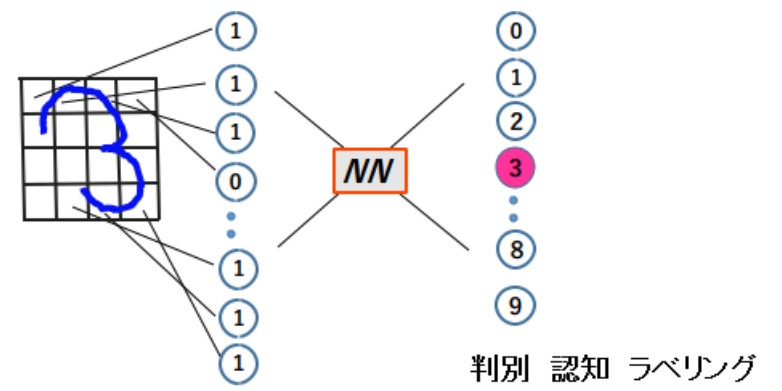
次元の大きいベクトル(上の例では16次元のベクトル)を、次元の小さいベクトル(上の例では10次元のベクトル)に変換することは、NN内部の接続シナプスにおける結合の荷重(接続係数)を、適切に調節することによって、可能となる。このように、ベクトルの次元を低減するようなNNが存在するとき、その出力側ベクトルは、判別の結果を表すものとなる。つまり、手書きの数字が何の数字なのかを判別することができる。このようにNNがベクトルの次元を下げる働きをするとき、そのNNは判別をしたとか、認知をしたとか、ラベリングをしたとか言うのである。これが画像における認知の基本であり、ヒトの視覚系における認識の基本である。
画像におけるAttention
先に記したattentionは、翻訳だけでなく、画像の解析にも役立つ。視野の中の丸い形、即ち、ボールに注目すれば、それが、画面の中のどこを移動していくかを追いかけることができる。動画のコマにある円形の物と次のコマにある類似の物が。同じものであることは、2コマの画像ベクトル間の内積で判断できる。空間を移動するボールに注目して、その軌跡の形を判定する。これが、世界を理解することであり、世界を脳内に写像することである。厳密にいえば、ニュートンの運動方程式の特性を学習し、NNの中に記憶し、それを基にNNの中でボールを投げ上げる動作を作り出せば(計算すれば)、放り上げたボールが画像内のどのあたりを通過して落ちてくるか、予測できる。実際に重力の法則を知らなくても、ボールの動きは経験的に予測可能と思われる。脳内のNNは、それに近い計算を自然に身に着けており、身体を動かしながらの練習によって、その精度を上げることができるのである。ボールという形態に注目することが、一種の attention であると考えれば、その重要性が理解できる。Attention は意識を支える重要な要素である。
どうぞ、下記欄にコメントをお寄せください。